Integrare ExeWatch in Progetti Delphi che Già Usano madExcept
TL;DR: Non devi scegliere. Se usi già madExcept, tienilo. Aggiungi la unit bridge al tuo progetto e ogni eccezione che madExcept intercetta finisce anche nella dashboard di ExeWatch — con lo stack trace già risolto da madExcept. Nessun upgrade della SDK, nessuna modifica alla configurazione madExcept esistente.
Il Timore, Raccontato da un Cliente Vero
Qualche giorno fa un nostro cliente — sviluppatore Delphi di lunga data, utente madExcept dai primi anni Duemiladieci — ci ha posto questa domanda:
“Uso madExcept da anni. Il dialog locale, l’email automatica, lo zip del bug report — fanno parte del modo in cui la mia applicazione segnala problemi. Se aggiungo ExeWatch, devo buttare via tutto?”
La risposta breve è no. La risposta lunga è l’argomento di questo articolo.
Qualcuno potrebbe pensare che ExeWatch e madExcept siano alternative, ma non lo sono. Risolvono problemi che si sovrappongono in superficie ma arrivano da direzioni opposte, e quando li metti insieme ottieni qualcosa di meglio di ciascuno dei due presi singolarmente. In questo post ti spiego esattamente perché, e ti mostro l’integrazione in pratica.
Cosa Fa Bene Ciascuno dei Due
Prima di parlare di integrazione vale la pena essere precisi su cosa eccelle ciascuno dei due strumenti. La confusione attorno al “ExeWatch contro madExcept” nasce quasi sempre dall’assumere che facciano lo stesso mestiere — e invece no.
madExcept: l’ultima linea di difesa sulla macchina dell’utente
madExcept vive in profondità nel processo. Quando scatta un’eccezione, madExcept è in grado di:
- Risolvere lo stack trace con nomi delle unit e numeri di riga, usando le informazioni di debug embeddate in fase di link (così non devi distribuire i file
.mapinsieme all’eseguibile) - Mostrare un dialog locale all’utente, permettendogli di aggiungere un commento prima dell’invio
- Salvare su disco un bug report completo — con module list, dump dei registri, lista dei thread, screenshot — e conservarlo anche quando la rete è assente
- Inviare il report via email o caricarlo su un endpoint FTP/HTTP in automatico
- Rilevare blocchi del thread principale e memory leak
madExcept è uno strumento di riferimento nell’ecosistema Delphi da oltre due decenni, adottato da migliaia di sviluppatori in altrettante applicazioni desktop di produzione. È solido, maturo, ed è una di quelle librerie che fa bene ciò che fa da così tanto tempo che è difficile immaginare di costruire un’app Delphi desktop senza. Se il tuo workflow dipende dal ricevere crash report via email, o dal permettere agli utenti finali di fornire contesto tramite un dialog, madExcept fa un lavoro che nessun tool APM cloud-first è progettato per sostituire.
ExeWatch: cosa succede dopo che il crash report è partito
ExeWatch comincia dove madExcept si ferma. Una volta che un errore è successo, le domande interessanti non sono più “qual era lo stack?” ma diventano:
- È un bug nuovo o già noto? È capitato su altre installazioni, su altre versioni dell’app, nelle ultime 24 ore?
- Cosa stava facendo l’utente poco prima? Breadcrumb — click sui bottoni, navigazioni, richieste HTTP — catturati automaticamente dalla SDK.
- Con che frequenza sta scattando in produzione? Tra i clienti, tra le versioni, nel tempo.
- Sta colpendo un solo cliente o molti? ExeWatch ti mostra device, clienti, sessioni.
- C’è un trend? Health score, alert, anomaly detection.
- Cosa stava succedendo intorno? Timing/profiling di operazioni lente, metriche custom, log di info che hanno preceduto l’errore.
ExeWatch aggrega log, timing, metriche e salute su tutte le installazioni della tua applicazione e ti dà una dashboard per cercare e correlare. Risponde alla domanda “la mia app sta davvero funzionando bene là fuori?”, non alla domanda “cosa è appena crashato sulla macchina di questo utente?”.
E qui arriva un punto che vale la pena sottolineare: un’applicazione che non crasha mai può avere comunque clienti scontenti. Un’operazione che l’utente percepisce lenta senza mai segnalarla, un import che fallisce con un messaggio generico, una chiamata HTTP che va in timeout solo sulle reti di un certo paese, un trend d’errore che cresce silenziosamente nell’arco di settimane, un flusso di checkout che rallenta quando il database è sotto carico — sono problemi che non compaiono mai in un crash report e che nessuna integrazione “solo-crash” potrà mai vedere, eppure erodono giorno dopo giorno la percezione di qualità del tuo software. ExeWatch è pensato per questi scenari almeno quanto per i crash.
In questa cornice madExcept fornisce un pezzo molto dettagliato del puzzle — il pezzo quando c’è un crash. ExeWatch prende quel pezzo e lo inserisce in un’immagine molto più ampia, fatta anche di timing, metriche, trend, breadcrumb e health. Non è un caso che un’applicazione possa essere “stabile” — zero crash in sei mesi — e al tempo stesso lasciare gli utenti frustrati da rallentamenti, errori silenziosi o regressioni di performance che nessun handler di eccezione vedrà mai.
Perché a Prima Vista Sembra Che Si Pestino i Piedi
Quando un utente aggiunge ExeWatch a un’app che ha già madExcept, tipicamente nota qualcosa di strano: le eccezioni non gestite non arrivano mai alla dashboard di ExeWatch, anche se gli altri log sì.
La causa è una questione di ordine. L’auto-capture delle eccezioni GUI di ExeWatch si aggancia a Application.OnException della VCL. L’hook di madExcept invece è installato a un livello più basso — sostanzialmente tra il sistema operativo e la RTL — e parte prima che l’handler VCL venga chiamato. Una volta che madExcept ha gestito l’eccezione (mostrando un dialog, inviando un’email o riavviando l’applicazione), l’handler VCL non viene più raggiunto. Di conseguenza, l’hook di ExeWatch non vede mai l’eccezione.
Non è un bug di nessuno dei due. È così che madExcept è progettato per funzionare, e la stessa cosa succede se lo metti in catena con qualsiasi altra libreria che vuole vedere le eccezioni non gestite (Sentry, EurekaLog, framework di logging custom). Chi aggancia per primo vince.
La risposta non è rimuovere uno dei due hook — servono entrambi. La risposta è lasciare che sia madExcept a catturare l’eccezione per primo, e poi fargli passare esplicitamente una copia a ExeWatch dall’interno del suo callback. Questo è un punto di estensione documentato di madExcept e si chiama RegisterExceptionHandler.
Il Bridge: Un’Unica Unit
Ecco il bridge completo. Aggiungi questo file al tuo progetto, inseriscilo nella clausola uses del .dpr, e hai finito — la sezione initialization installa il callback in automatico:
unit ExeWatchMadExceptBridgeU;
interface
implementation
uses
System.SysUtils,
System.JSON,
madExcept,
ExeWatchSDKv1;
procedure ExeWatchMadExceptHandler(const ExceptIntf: IMEException;
var Handled: Boolean);
var
ExtraData: TJSONObject;
ExClass, ExMsg: string;
E: TObject;
begin
if (ExceptIntf = nil) or (not ExeWatchIsInitialized) then
Exit;
E := ExceptIntf.ExceptObject;
if Assigned(E) and (E is Exception) then
begin
ExClass := E.ClassName;
ExMsg := Exception(E).Message;
end
else
begin
ExClass := ExceptIntf.ExceptClass;
ExMsg := ExceptIntf.ExceptMessage;
end;
ExtraData := TJSONObject.Create;
ExtraData.AddPair('exception_class', ExClass);
ExtraData.AddPair('exception_message', ExMsg);
ExtraData.AddPair('stack_trace', ExceptIntf.BugReport);
EW.Log(llError, ExMsg, 'exception', ExtraData);
// Handled viene deliberatamente lasciato invariato: dialog, bug report
// ed email di madExcept continuano a girare esattamente come prima.
end;
initialization
RegisterExceptionHandler(ExeWatchMadExceptHandler, stDontSync);
finalization
UnregisterExceptionHandler(ExeWatchMadExceptHandler);
end.
Tutto qui. Tre osservazioni che vale la pena sottolineare:
1. Il callback non “consuma” l’eccezione. Handled viene lasciato invariato, quindi la pipeline normale di madExcept — dialog, email, salvataggio del bug report — continua esattamente come prima che il bridge esistesse. L’utente finale vede la stessa esperienza.
2. stDontSync permette al callback di girare su qualsiasi thread. L’API di logging di ExeWatch è thread-safe, quindi non serve che madExcept faccia marshalling sul thread principale. Conta nei servizi o nelle app con molti worker thread, dove una sync forzata potrebbe creare stalli.
3. Lo stack trace mandato a ExeWatch è quello di madExcept, non quello della SDK. Questo è il dettaglio che quasi tutti perdono. ExceptIntf.BugReport contiene lo stack completamente risolto — nomi delle unit, numeri di riga, module list, registri — grazie alle informazioni di debug che madExcept ha embeddato in fase di link. Passiamo quella stringa a ExeWatch tramite il campo extra_data.stack_trace. Il metodo Log della SDK rispetta uno stack_trace fornito dal chiamante e non lo sovrascrive, quindi in dashboard vedi i frame risolti di madExcept anziché indirizzi grezzi.
Cosa Ottieni Davvero
Dopo aver installato il bridge, il percorso di un’eccezione è questo:
- Un’eccezione scatta da qualche parte nel tuo codice
- madExcept la intercetta — esattamente come prima
- Il nostro callback gira mentre madExcept sta ancora processando
- Spediamo a ExeWatch un log di livello ERROR con lo stack di madExcept
- Il flusso normale di madExcept continua senza modifiche: dialog, bug report, email al team di sviluppo, eventuale restart
Il risultato netto è che per ogni eccezione adesso hai entrambe le cose:
- Sulla macchina locale: tutto quello che madExcept ha sempre fatto — dialog, file di report, email
- Nella dashboard cloud di ExeWatch: la stessa eccezione, con lo stack risolto da madExcept, insieme a breadcrumb, session ID, info sul device, customer ID, versione dell’app e tutti gli altri log che la SDK ha raccolto intorno
Visivamente, il contrasto è questo.
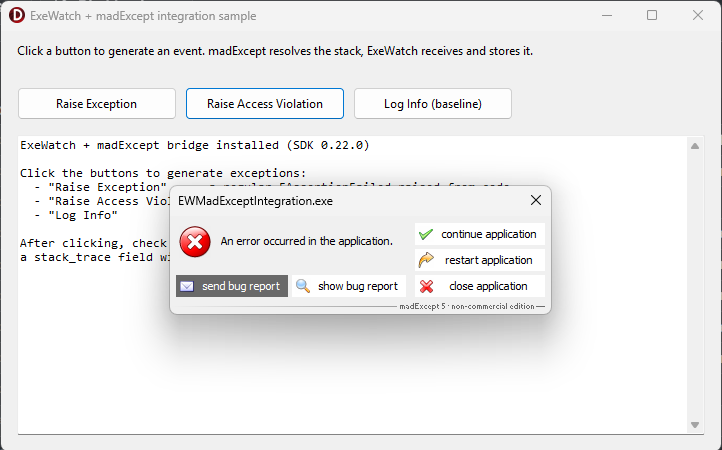
Sul PC dell'utente: madExcept fa il suo lavoro di sempre — dialog di errore locale con i pulsanti send bug report, continue application, restart, close. L'esperienza dell'utente finale non cambia di una virgola.
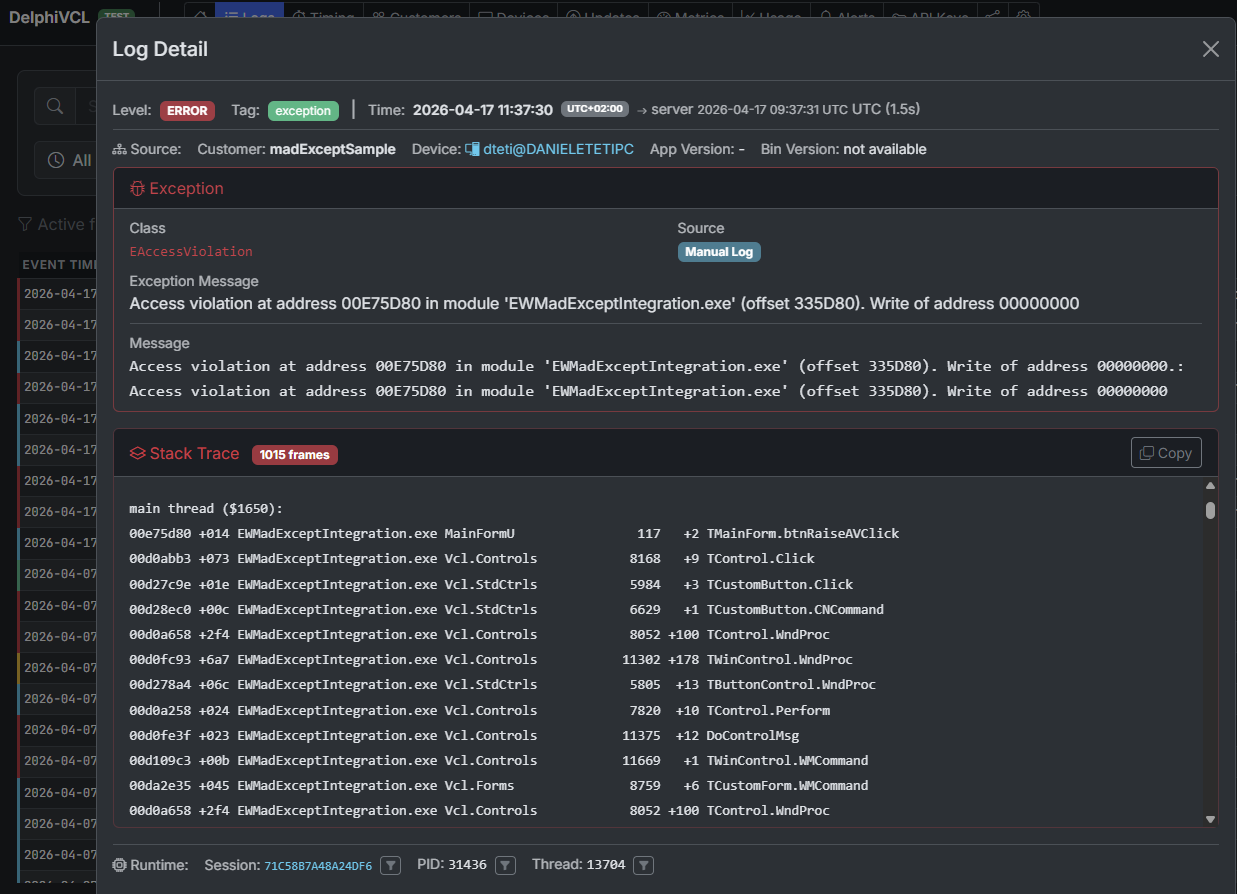
Nella dashboard di ExeWatch, dallo schermo dello sviluppatore: la stessa eccezione — qui un EAccessViolation — arriva aggregata, con lo stack trace già risolto da madExcept (nomi delle unit, numeri di riga, offset dei moduli) e tutto il contesto raccolto dalla SDK (sessione, thread, device, breadcrumb, timing).
Il valore della seconda non è un duplicato della prima. madExcept ti racconta un crash. ExeWatch ti dice:
- Sta succedendo solo sulla v2.3.1?
- Gli utenti Windows 10 lo vedono più di quelli Windows 11?
- È cominciato dopo l’ultimo deploy?
- Quale cliente lo ha visto per primo?
- Cosa ha cliccato l’utente subito prima?
- I device colpiti hanno in comune un certo antivirus?
Sono domande di correlazione e di trend per cui serve un livello di aggregazione diverso — quello che ExeWatch fornisce. Non è un limite di madExcept: sono piani differenti dello stesso problema, e madExcept continua a fare il suo egregiamente nel suo piano.
Un Esempio Concreto
Immagina un’applicazione che usa madExcept da anni, con il suo workflow di email-report ben collaudato. Ogni eccezione genera un dialog, l’utente clicca “Invia”, il team di sviluppo riceve uno zip via email — ricco, dettagliato, ottimo per capire il singolo caso. Con la crescita dell’installato diventa utile anche un secondo livello di lettura, complementare al primo: raggruppamento per versione, conteggio per cliente, trend nel tempo.
Aggiungi ExeWatch a fianco. Installa il bridge. Deploya.
Dal giorno dopo:
- Il flusso email è invariato — il team continua a ricevere i bug report esattamente come prima.
- La dashboard di ExeWatch mostra ora ogni eccezione, raggruppata per fingerprint (classe + stack), con conteggi per versione e per cliente.
- Configuri un alert: “se gli errori superano 3 in 10 minuti, mandali su Discord”. La prima regressione vera dopo un deploy viene colta in pochi minuti, prima che gli utenti inizino a telefonare.
- Una regola di anomaly detection individua un aumento graduale di una specifica eccezione nell’ultima settimana — un memory leak lento che si manifesta solo dopo alcune ore d’uso — che emerge grazie all’aggregazione temporale sulla flotta di installazioni.
madExcept continua a fare il suo lavoro. ExeWatch fa un lavoro diverso. Nessuno dei due rimpiazza l’altro.
Prerequisiti e Dove Trovare il Codice
Il sample completo, con una form dimostrativa che scatena volutamente eccezioni normali, access violation e log di info di baseline, si trova nel repository di esempi di ExeWatch:
github.com/danieleteti/ExeWatchSamples › SpecificScenarios/madExceptIntegration
Nel sample trovi:
ExeWatchMadExceptBridgeU.pas— il singolo file da mettere nel tuo progettoEWMadExceptIntegration.dproj— un progetto demo Delphi 12+ eseguibile (Win32 + Win64)MainFormU.pas/.dfm— tre bottoni per scatenare un’Exception normale, un access violation e un log di info di confrontoEWMadExceptIntegration.mes— il file di settings madExcept, così che aprendo il progetto madExcept venga linkato automaticamenteREADME.md— istruzioni passo-passo più varianti (inviare solo il call stack invece dell’intero bug report, filtrare le eccezioni non-crash, equivalente EurekaLog)
Requisiti:
- madExcept installato nell’IDE — disponibile su madshi.net
- Delphi XE8 o più recente — il bridge usa solo feature standard della RTL (System.JSON, scoped unit names, try/except con Exception tipizzata)
- SDK ExeWatch v0.21.0 o più recente — qualsiasi versione recente va bene; non serve una build speciale
- Un account ExeWatch — il piano Hobby è gratuito, senza carta di credito
Lo stesso pattern si estende a EurekaLog tramite il suo callback RegisterEventExceptionNotify. La logica è identica: estrai lo stack risolto dall’exception info di EurekaLog, costruisci lo stesso payload extra_data, chiami EW.Log. Aggiungeremo un sample EurekaLog dedicato al repository nelle prossime settimane.
La sezione di integrazione completa, con un anchor diretto da condividere, è documentata anche su exewatch.com/ui/docs#coexisting-madexcept.
E Senza madExcept?
Dopo tutto questo viene spontaneo chiedersi: posso avere uno stack trace accurato anche se non uso madExcept?
Sì. La SDK Delphi di ExeWatch cattura lo stack nativamente a ogni chiamata EW.Error, EW.Fatal ed EW.ErrorWithException. L’unico vincolo operativo, al momento, è che per leggere nomi di unit e numeri di riga invece di indirizzi di memoria grezzi occorre distribuire il file .map insieme all’eseguibile — generato abilitando “Detailed” come Map file nelle Linking options del progetto. È un passaggio aggiuntivo al rilascio, ma risolve il problema.
madExcept sposta quel passaggio a link time, embeddando le informazioni di debug dentro l’eseguibile stesso, ed è il motivo per cui quando è presente ci appoggiamo al suo stack già risolto. Stiamo valutando modi per rendere il .map non necessario anche in assenza di madExcept — per info, feedback o segnalazioni scrivi a exewatch@bittime.it.
Non Scegliere — Integra
Se stai valutando ExeWatch e temi che voglia dire abbandonare uno strumento su cui hai fatto affidamento per anni, stai tranquillo. madExcept e ExeWatch non sono duplicati; sono livelli differenti della stessa storia di osservabilità. Il livello locale — dialog, report, dump — è quello che madExcept sa fare meglio. Il livello cloud — aggregazione, ricerca, alert, trend — è quello che ExeWatch sa fare meglio.
Una singola unit bridge è tutto ciò che serve per farli lavorare insieme, e quando lo fanno ottieni una vista sulla salute della tua applicazione che nessuno dei due strumenti da solo può offrirti.
Link e Risorse
- ExeWatch: exewatch.com
- Sample di integrazione madExcept: github.com/danieleteti/ExeWatchSamples › SpecificScenarios/madExceptIntegration
- Documentazione — Coesistenza con madExcept / EurekaLog: exewatch.com/ui/docs#coexisting-madexcept
- madExcept: madshi.net
- Articolo precedente: ExeWatch 1.8: SDK .NET, Metriche Custom, Health Monitoring e On Premise
ExeWatch — Monitoring per applicazioni server, desktop e web. Realizzato da bit Time Professionals.
Comments
comments powered by Disqus