Lehman's Laws of Software Evolution: Why Code Rots
All eight of Lehman's laws of software evolution, explained with practical scenarios, symptoms, and fixes for working software teams.🇮🇹 Italiano • 🇩🇪 Deutsch • 🇪🇸 Español • 🇧🇷 Português
Eight empirical laws of software evolution, from IBM's OS/360 to the Linux kernel: why software rots, why complexity grows on its own, and what deliberate effort buys back.
Software doesn’t break the way bridges break. A bridge that is never touched can still stand for fifty years or more, and some stand far longer. A codebase that is never touched does the opposite: it quietly rots. The world around it shifts (operating systems update, APIs deprecate, regulations change, users expect more) and the untouched program, frozen in place, becomes a little less useful every single day until one morning it simply stops working.
This isn’t an opinion. It’s closer to physics. More than fifty years ago, a researcher at IBM noticed that large software systems behave according to surprisingly consistent patterns as they age, and he spent two decades turning those observations into a set of empirical laws now known as Lehman’s laws of software evolution. They still describe your sprint board today, whether you’ve heard of them or not.
Let’s meet the laws, where they came from, where they hold up, where they break, and, most importantly, how to use them on real projects this quarter.
A study that accidentally founded a field

{kind=link}
In the late 1960s, IBM was building OS/360, one of the most ambitious software projects of its era. Meir “Manny” Lehman, together with his colleague László Bélády, began studying the release history of that system, measuring how its size, its defect counts, and the effort to change it evolved release over release. (Bélády and Lehman published an early model of this in the IBM Systems Journal in 1976.)
What started as three observations in 1974 grew to five by 1978 and, by 1996, to a set of eight Laws of Software Evolution. Lehman is now widely regarded as the father of the entire research field of software evolution. When he died in 2010, the academic community memorialized him exactly that way.
One subtlety matters before we go further, because it’s where most casual summaries get sloppy. Lehman didn’t claim these laws apply to all software. He classified programs into three types, the SPE classification:
- S-type programs are defined entirely by a fixed Specification. A function that computes a mathematical result is correct or incorrect against that spec, full stop. It need never change.
- P-type programs solve a real-world Problem with an approximate solution (think a chess engine) where the problem is stable but our solution can always improve.
- E-type programs are Embedded in the real world. They mechanize a human or business activity and become part of the world they model. A banking platform, an e-commerce checkout, a hospital records system. The moment they go live, they change the environment, which changes the requirements, which forces the software to change again.
The eight laws describe E-type systems, and almost everything you ship for a living is E-type. That’s why these laws feel personal.
The eight laws of software evolution at a glance
| # | Law (year) | What it says, in one line |
|---|---|---|
| 1 | Continuing Change (1974) | A system used in the real world must keep changing, or it becomes progressively less useful. |
| 2 | Increasing Complexity (1974) | Complexity rises as the system evolves, unless you spend effort to reduce it. |
| 3 | Self-Regulation (1974) | Evolution is self-regulating; release metrics stay close to stable, normal-shaped trends. |
| 4 | Conservation of Organisational Stability (1978) | The effective work rate stays roughly constant, largely independent of headcount. |
| 5 | Conservation of Familiarity (1978) | Everyone must keep mastering the system, so incremental change per release stays bounded. |
| 6 | Continuing Growth (1991) | Functional content must keep growing to keep users satisfied over the system’s life. |
| 7 | Declining Quality (1996) | Quality appears to decline unless the system is rigorously maintained and adapted. |
| 8 | Feedback System (1996) | Evolution is a multi-level, multi-loop, multi-agent feedback system. |
The laws aren’t eight unrelated facts, either. They reinforce one another into a single dynamic that pushes a system toward decay, and a single counter-force that holds it back:
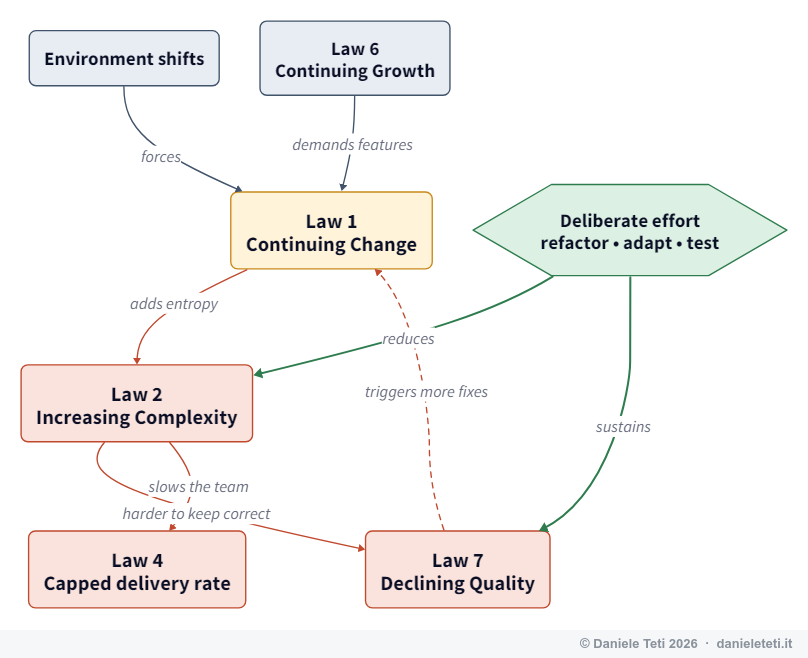
Law 1: Continuing Change
“An E-type system must be continually adapted or it becomes progressively less satisfactory.”
This is the foundation. The value of an E-type program isn’t fixed; it’s defined relative to a moving environment. Hold the software still and the gap between what it does and what the world needs widens on its own.
Practical scenario. Your e-commerce app integrates with a payment gateway. You wrote that integration two years ago and it has worked flawlessly, and nobody has touched it. Then the gateway announces it is dropping support for TLS 1.1 and changing its webhook signature format in 90 days. You wrote zero bugs, yet your “finished” feature is now a countdown timer to a production outage. Continuing Change means no module is ever truly done; it’s only done for now. The engineering response is to budget for maintenance you can’t yet name, and to design integration points (adapters, versioned interfaces) so that “the world moved” costs you a small change instead of a rewrite.
Law 2: Increasing Complexity
“As an E-type system evolves, its complexity increases unless explicit work is done to maintain or reduce it.”
Notice the phrasing: complexity rises by default. It is the natural entropy of a system under continuous change. Every feature added under deadline, every special case bolted onto an existing flow, every “we’ll clean this up later” raises the structural disorder. Reducing complexity is the only thing that requires deliberate effort, and that effort is rarely on the roadmap.
Practical scenario. A startup’s checkout begins as one clean function. Marketing wants a promo-code path, so an if is added. Then a B2B invoice path. Then a gift-card path. Then regional tax exceptions. Eighteen months later, that function is 600 lines with 40 interacting flags, and every change risks breaking a path nobody remembers. Law 2 tells you this was not a failure of discipline by one bad developer: it’s the expected trajectory. The countermeasure is to treat refactoring as a recurring line item, not a heroic one-off: a standing “complexity budget” (say, 15–20% of each sprint) spent on extracting modules, deleting dead branches, and keeping cyclomatic complexity in check. Microservice boundaries and clean-architecture seams are tactics, but the strategic point is simpler: if you don’t spend energy fighting complexity, complexity wins. (This is exactly what Lean thinking calls eliminating waste: complexity that no longer earns its keep is muda, and pruning it is real work, not overhead.)
Law 3: Self-Regulation
“E-type system evolution processes are self-regulating, with the distribution of product and process measures close to normal.”
This is the law most often mangled in summaries (it is not about “large program evolution”). Lehman observed that a system’s evolution behaves like a regulated organism. Measures such as release size and growth rate fluctuate around a stable trend, with the bumps and dips roughly canceling out. Push hard in one release and the system tends to compensate: a feedback mechanism pulls it back toward its long-run rate.
Practical scenario. A product manager, frustrated with steady progress, mandates a blockbuster release: triple the normal scope in one quarter. The team complies. The result is predictable to anyone who knows this law: defect counts spike, the following release shrinks dramatically as the team absorbs the fallout, and the two-release average lands almost exactly on the historical trend line. The actionable insight is a gift to planners: your own release history is a forecasting tool. If your last ten releases averaged ~30 story points of net new functionality with a defect-arrival pattern that’s roughly normal, a plan that assumes 90 is fighting gravity. Use the trend to set credible expectations, and treat a release that wildly exceeds it as a risk signal, not a triumph.
Law 4: Conservation of Organizational Stability
“The average effective global activity rate in an evolving E-type system is invariant over the product’s lifetime.”
The effective rate at which useful change gets delivered tends to stay roughly constant over a project’s life and, strikingly, it’s largely independent of the resources you throw at it. This is the law that overlaps with Fred Brooks’s famous observation in The Mythical Man-Month that “adding manpower to a late software project makes it later.”
Practical scenario. A project is three months behind. Leadership’s instinct is to add five engineers. But the new hires need to learn the domain, the existing team must stop building to onboard them, and the number of communication paths in the team grows quadratically (a 5-person team has 10 pairwise links; a 10-person team has 45). For the next two months, effective output drops. Conservation of Organizational Stability says throughput is governed less by headcount than by the system’s accumulated complexity and the organization’s communication structure. The leverage isn’t more people: it’s removing friction, cutting build and deploy times, paying down the complexity from Law 2, clarifying ownership, and shrinking feedback latency so each engineer’s effective rate goes up.
Law 5: Conservation of Familiarity
“As an E-type system evolves, all associated with it (developers, sales personnel, users) must maintain mastery of its content and behaviour to achieve satisfactory evolution. Excessive growth diminishes that mastery. Hence the average incremental growth remains invariant as the system evolves.”
Everyone connected to the system (developers, operators, support staff, and users) can only absorb so much change per release before they lose their grip on how it works. Releases that pack in too much novelty exceed that absorption budget, and quality and adoption suffer for it.
Practical scenario. A team attempts a “big bang” rewrite: a year of work, then a single release that replaces 70% of the product at once. On launch, support tickets flood in, the team can’t reason about which of the thousand changes caused which regression, and power users revolt against an interface they no longer recognize. Law 5 explains the failed UI redesigns we all remember: the ones where users started petitions to bring back the old version. The discipline it prescribes is to cap the novelty of each release, not just its size. Ship continuously in digestible increments, run new and old paths side by side behind flags, and give people time to build familiarity. The change your team and customers can understand is the real constraint, not the change you can code.
Law 6: Continuing Growth
“The functional content of an E-type system must be continually increased to maintain user satisfaction over its lifetime.”
Here’s the most-confused trio in the whole set, so let’s separate them cleanly. Law 1 (Change) is about adapting existing functionality to a shifting world. Law 2 (Complexity) is about internal disorder accumulating. Law 6 (Growth) is about the external feature surface needing to expand because user expectations ratchet upward and never reset. Yesterday’s delightful extra is today’s baseline assumption.
Practical scenario. A SaaS analytics product launches with five integrations and customers love it. Two years later, prospects walk away in sales calls because it lacks the Snowflake connector a competitor added last month. The product hasn’t gotten worse: its functional content simply stopped growing while expectations kept climbing, and the gap reads as decline. Law 6 is the engine behind every product roadmap and every “table stakes” feature list. The strategic catch is that Growth (Law 6) and Complexity (Law 2) pull against each other: every feature you add to satisfy users also raises entropy. Mature teams treat this as an explicit trade-off, pruning low-value features as aggressively as they add high-value ones, so growth doesn’t silently mortgage the codebase.
Law 7: Declining Quality
“The quality of an E-type system will appear to be declining unless it is rigorously maintained and adapted to operational environment changes.”
Note the precise word: quality will appear to decline. The code on disk hasn’t changed, but the standards it’s judged against have. The environment moved (new browsers, new devices, ten times the traffic, new security expectations) and a program that was excellent against 2019’s bar looks shabby against 2026’s.
Practical scenario. A monolith has run reliably for years. Nobody has introduced a bug. Yet users now complain it’s “slow and clunky.” What actually happened: mobile traffic went from 20% to 70% and the app was never designed for it; the dataset grew 50× and queries that were instant now crawl; competitors set a new baseline for responsiveness. Declining Quality says the antidote is active, not reactive: you must continuously adapt to the operational environment, not just fix reported defects. Practically, that means observability that tracks real-world performance against today’s expectations, regular load and security re-baselining, and automated testing plus CI/CD pipelines that make continuous adaptation cheap enough to actually do. Quality is not a state you reach; it’s a rate you sustain.
Law 8: Feedback System
“E-type evolution processes constitute multi-level, multi-loop, multi-agent feedback systems.”
This is the capstone, and it reframes all the others. Evolving a large system isn’t a linear pipeline from requirement to code. It’s a web of feedback loops: users react to releases, support data flows to product, product decisions constrain engineering, engineering reality reshapes the roadmap, organizational structure shapes the architecture (Conway’s Law lurking nearby). Because the loops interact, local changes produce non-local, often counter-intuitive effects.
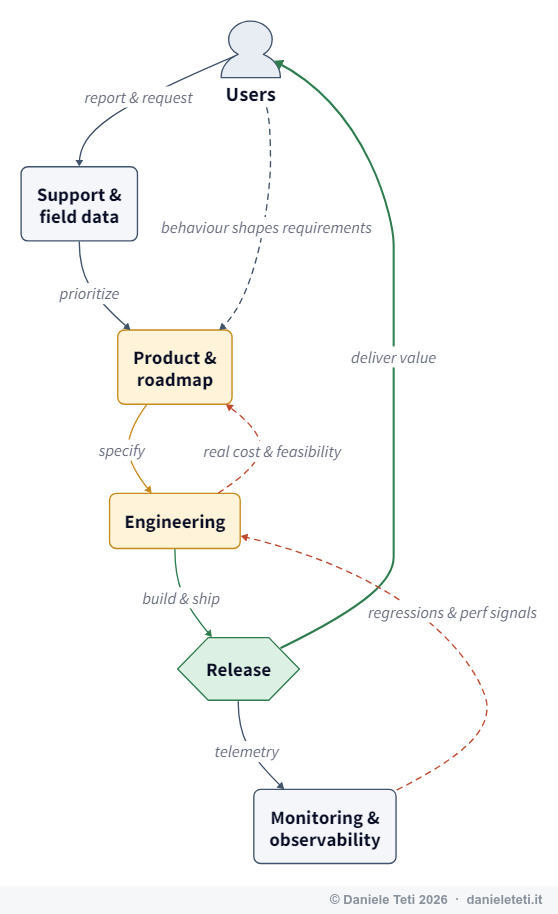
Practical scenario. A VP, hoping to lift quality, mandates a new rule: every pull request needs three approvals. The intended loop says “more review → fewer bugs.” The actual system says otherwise: review queues back up, engineers batch larger PRs to amortize the overhead, large PRs get rubber-stamped because nobody can review 2,000 lines carefully, and defect rates rise. Law 8 warns that you can’t reliably steer a feedback system by tweaking one variable and assuming the rest holds still. The discipline it demands is humility plus measurement: change one thing, instrument the loops, watch for second-order effects, and adjust, exactly the empirical, hypothesis-driven posture that good DevOps and continuous-improvement cultures encode.
Where the laws bend, and why that’s the most useful part
A 50-year-old theory built on a 1960s mainframe deserves scrutiny, and it has received plenty. The most important challenge came from open source.
In 2000, Michael Godfrey and Qiang Tu studied the Linux kernel across 96 releases from 1994 to 2000 and found something the laws didn’t predict: the kernel grew at a super-linear rate. That directly contradicted the inverse-square growth model Lehman and Turski had derived from commercial systems, where growth was expected to slow as size and complexity made each change harder. A massively parallel, globally distributed, volunteer development model apparently rewrote the growth curve. Later long-lived open-source studies found the laws hold unevenly: Continuing Change proves remarkably robust, but others (Conservation of Familiarity, and the predicted growth dynamics themselves) often fail to hold once a project’s context shifts (for example, when it enters a maintenance phase or grows through mass parallel contribution).
Why do the laws bend exactly here? The deviation isn’t random: it comes down to many factors, and the first of them is that the forces driving feature growth are not the same. Lehman derived his laws from commercial systems, where what gets built is ultimately governed by the market: features are added to win deals, retain customers, and protect revenue, and that economic pressure shapes release cadence, scope, and the constant tug-of-war between new functionality and stability. An open-source kernel answers to a completely different set of incentives. A feature lands in Linux because a contributor needs it for their own hardware, because a vendor upstreams a driver, because maintainers judge it technically sound and worth the long-term maintenance burden, not because it moves a revenue number or appears on a sales roadmap. There is no quarter to hit, no churn metric, no pricing tier to protect. And with thousands of independent contributors each scratching their own itch in parallel, growth isn’t throttled by a single organisation’s capacity (Law 4) or by what one team can stay familiar with (Law 5), so it can run super-linear in a way Lehman’s commercial datasets never showed. The criteria that decide whether a feature exists at all are simply different from the commercial ones the laws were calibrated on.
That reframes the whole result. Several of Lehman’s laws are, at heart, statements about the organisation producing the software (its economics, its capacity, its incentives) as much as about the code itself. Change the engine that drives the work, and the measurable behaviour changes with it. The Linux kernel didn’t break the laws; it ran on a different engine than the one Lehman observed.
This is not a reason to discard the laws. It’s the reason to respect them. Lehman’s laws are empirical generalizations about a particular regime: closed, commercially developed, organizationally bounded systems. When you change the regime fundamentally (the economics, the parallelism, the contributor model), some laws bend and others snap. Knowing which laws are robust (change is inevitable, complexity rises without effort, feedback dominates) and which are conditional (the precise growth curve, the self-regulating cadence) is exactly the kind of judgment that separates engineers who quote principles from engineers who use them.
The one idea to keep
Strip away the formality and the eight laws collapse into a single, uncomfortable truth:
Left alone, it falls out of step with the world (Law 1), accumulates internal disorder (Law 2), looks worse against rising standards (Law 7), and starves its users of the growth they now expect (Law 6), while feedback loops you don’t fully control (Law 8) resist your attempts to manage it, and your raw headcount can’t buy your way out (Law 4).
The teams that thrive aren’t the ones that escape these forces (nobody does). They’re the ones who plan for them: who budget for maintenance before it’s urgent, who spend continuous effort fighting complexity, who size each release to what people can absorb, who treat quality as a sustained rate rather than a finish line, and who steer their process by measuring its loops instead of issuing decrees into them.
There’s a name for that posture. If Lehman’s laws describe the disease (entropy that accumulates, complexity that grows on its own, quality that slips as the world keeps moving), then Lean thinking is the closest thing we have to a treatment: relentlessly remove waste (muda), keep batch sizes small so people never lose their grip on the system (which is precisely Lehman’s Conservation of Familiarity), build quality in instead of inspecting it back afterwards, and let feedback loops, not edicts, steer the work (Lehman’s Eighth Law, restated as a management practice). It isn’t a forced analogy: the two frameworks describe the same system from opposite ends, one names the forces, the other the discipline that answers them.

Lean Thinking for Busy Software Developers
Lehman's laws name the forces that drag every codebase toward decay. This book is the field manual for pushing back. It takes Toyota's Lean principles to the codebase: cut the invisible waste in your process, keep batches small (Conservation of Familiarity in practice), build quality in instead of inspecting it back, and steer with feedback loops instead of edicts, with concrete examples, DORA metrics, and a full chapter on working with AI agents.
Get it on Leanpub → Learn moreI cover these topics in a software engineering course
It's a course companies regularly ask us to run for their teams, and Lehman's laws are only one part of it. The course is genuinely dense: principles, the symptoms that reveal trouble early, and the concrete solutions that work in real systems, all packed into a fast-moving program. If you want your team to spot these forces and act before they bite, get in touch.
Lehman watched a mainframe operating system teach him these lessons in the 1970s. Your distributed, cloud-native, AI-assisted codebase is teaching them again right now. The only question is whether you’re reading the curriculum, or being graded on a test you didn’t know you were taking.
Key takeaways
- Decay is the default. A real-world (E-type) system left untouched doesn’t stay still: it drifts out of step with its environment (Law 1) and appears to lose quality (Law 7).
- Complexity grows unless you fight it. Increasing Complexity (Law 2) is entropy; only deliberate refactoring reverses it. Budget for it, don’t hope for it.
- You can’t buy your way out with headcount. Conservation of Organisational Stability (Law 4), and Brooks’s Law, mean throughput is governed by complexity and communication, not raw staff count.
- Ship change people can absorb. Conservation of Familiarity (Law 5) caps how much novelty a team and its users can take per release. Small batches beat big-bang rewrites.
- Keep growing, but prune. Continuing Growth (Law 6) is mandatory for satisfaction, yet every feature raises complexity, so treat it as an explicit trade-off.
- Steer the loops, not the variables. Evolution is a feedback system (Law 8); change one thing, measure the second-order effects, and adjust.
- The laws bend, so use judgment. They hold unevenly across modern and open-source projects, so know which are robust and which are conditional.
Frequently asked questions
What are Lehman’s laws of software evolution?
They are eight empirical observations, formulated by Meir M. Lehman between 1974 and 1996, describing how E-type software systems (those embedded in the real world) inevitably change, grow, and degrade over time unless deliberate effort is invested. The set covers Continuing Change, Increasing Complexity, Self-Regulation, Conservation of Organisational Stability, Conservation of Familiarity, Continuing Growth, Declining Quality, and Feedback System.
What is an E-type system?
In Lehman’s SPE classification, an E-type program is one embedded in the real world that mechanizes a human or business activity, like a banking platform or an e-commerce checkout. Unlike S-type programs (defined by a fixed specification) and P-type programs (an approximate solution to a stable problem), an E-type system changes the very environment it models, which forces it to keep evolving. The eight laws describe E-type systems.
Do Lehman’s laws still hold for modern and open-source software?
Partly. Replication studies found the laws hold unevenly. Continuing Change is remarkably robust, but others bend once the development regime changes. Godfrey and Tu’s 2000 study of the Linux kernel found super-linear growth that contradicted the inverse-square growth model Lehman derived from commercial systems, and later FLOSS studies found laws such as Conservation of Familiarity often fail to hold.
Why does software quality seem to decline even when no one changes the code?
Because of Lehman’s Seventh Law, Declining Quality: an E-type system’s quality is judged against a moving environment. As browsers, devices, traffic volumes and user expectations advance, untouched software looks progressively worse even though its code never changed. The antidote is continuous adaptation to the operational environment, not just reactive bug-fixing.
Why doesn’t the Linux kernel follow Lehman’s growth law?
Because the kernel runs on different incentives than the commercial systems Lehman studied. His growth model assumed feature growth is governed by market and revenue pressure inside a single organisation of bounded capacity. In open source, features are added because contributors need them for their own hardware, vendors upstream drivers, or maintainers judge them technically sound, not to hit a revenue target or a sales roadmap. With thousands of independent contributors working in parallel, growth isn’t throttled by one organisation’s capacity, so Godfrey and Tu (2000) measured super-linear growth instead of the predicted slowdown. The law didn’t fail; the kernel runs on a different engine, because the criteria that decide whether a feature exists are different from the commercial ones the laws were calibrated on.
Sources and further reading: Bélády & Lehman, “A Model of Large Program Development,” IBM Systems Journal (1976); Lehman, “Laws of Software Evolution Revisited” (1996); Godfrey & Tu, “Evolution in Open Source Software: A Case Study” (2000); Canfora et al., “In memory of Manny Lehman, ‘Father of Software Evolution’” (2011); and González-Barahona et al., “Studying the laws of software evolution in a long-lived FLOSS project” (2014).
Comments
comments powered by Disqus